Biography
Tyler is a Statistical Consultant at the Cornell Statistical Consulting Unit at Cornell University. He completed a postdoc in the Department of Psychology and the Center for Integrative Developmental Science at Cornell University with Anthony Ong. He received his Ph.D. in Quantitative Psychology at the University of Notre Dame. He has contributed to quantitative methods research for integrative data analysis and text mining and substantive research in psychology and clinical trials. He is generally interested in Bayesian statistics, multilevel modeling, topic modeling, statistical software development, and their application to advancing psychological and health research.
- Integrative data analysis
- Meta-analysis
- Multilevel modeling
- Topic modeling
- Statistical software development
- Developmental affective science
PhD Quantitative Psychology, 2022
University of Notre Dame
MS Applied Statistics, 2017
Rochester Institute of Technology
BS Psychology, 2013
Rochester Institute of Technology
Featured Publications
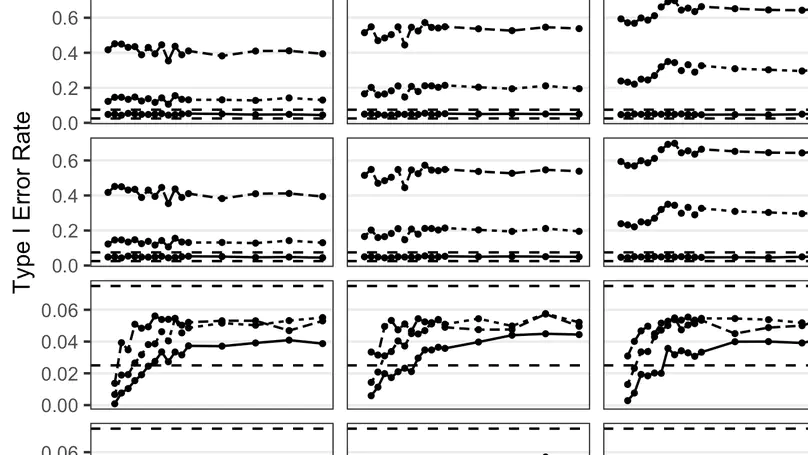
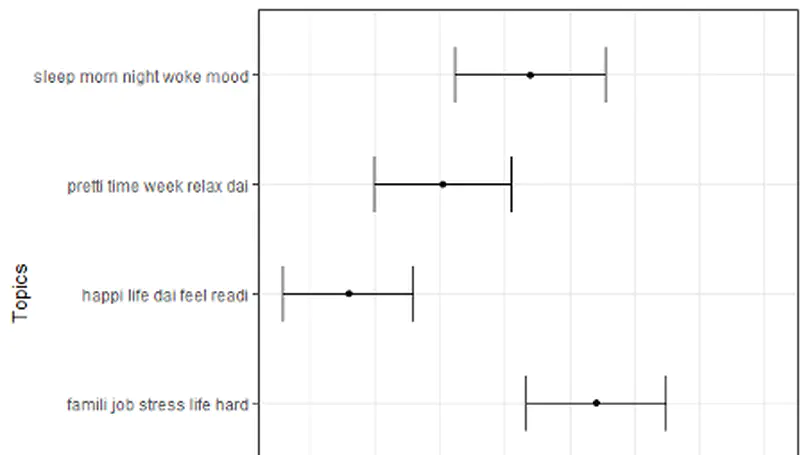

Recent Publications
Talks

Projects

Teaching
- PSY63199: Graduate Seminar: Quantitative Study (graduate course)
- PSY60101: Quantitative Methods II (graduate course)
- PSY61101: Quantitative Methods II Lab (graduate course)
- PSY60100: Quantitative Methods I (graduate course)
- PSY61100: Quantitative Methods I Lab (graduate course)
- STAT-731: Elements of Statistical Theory (graduate course)
- STAT-747: Principles of Statistical Data Mining (graduate course)
- STAT-611: Statistical Software (graduate course)
- STAT-511: Statistical Software
- MATH-252: Probability and Statistics II for Engineers