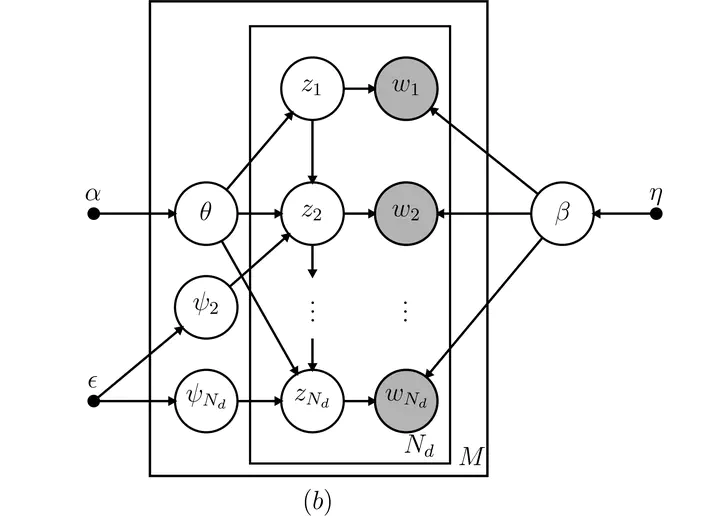
 Directed acyclic graph of the HTMM model.
Directed acyclic graph of the HTMM model.Abstract
Recent developments in topic modeling for text corpora have incorporated Markov models in the latent space to better learn contextual content. Known as the Hidden Topic Markov Model (HTMM), this natural extension of probabilistic mixture models relaxes the "bag-of-words" assumption of the foundational latent Dirichlet allocation topic model by allowing the discrete latent variables, or topics, to follow a special first-order Markov process. Parameter estimation is performed using an expectation-maximization (EM) algorithm with fixed dimensionality of the topic space (Gruber, Rosen-Zvi, and Weiss 2007). I fully derive the state space and EM algorithm for the HTMM. I then extend the Hidden Topic Markov Model (HTMM) into a fully Bayesian framework using a Gibbs sampler. The necessary full conditional distributions are derived and a Gibbs sampling algorithm proposed. I implement both the HTMM EM algorithm (Gruber, Rosen-Zvi, and Weiss 2007) and the HTMM Gibbs sampling algorithm in the R and C++ programming languages. The performance of both inferential algorithms is evaluated on twelve simulated data sets and on a collection of proceedings from the Conference on Neural Information Processing Systems (NIPS). The results suggest that the Gibbs sampling algorithm provides better recovery of the topic space than a combination of the EM and Viterbi algorithms. Parameter estimation is comparable using point estimates with both algorithms. The convergence of the Gibbs sampler is studied and is reliable for reasonably large data sets. Evaluation of both algorithms on the NIPS corpus suggests that the HTMM is better able to handle polysemy than LDA and provides coherent and contiguous topics. Predictive accuracy measured by perplexity is better on training and test documents using the HTMM than using LDA on the NIPS corpus. Introducing Markovian dynamics in topical space provides better topical segmentation of a corpus and increased predictive accuracy for unseen documents.
Kenneth Tyler Wilcox
Statistical Consultant
My research interests include integrative data analysis, meta-analysis, topic modeling, Bayesian statistics, multilevel modeling, statistical programming, and psychology.