The use of text-based responses to improve our understanding and prediction of suicide risk
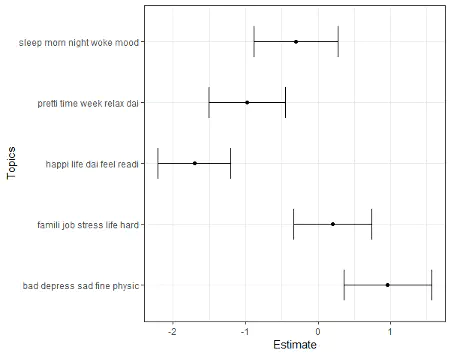 sLDA model with regression coefficients and 95% confidence intervals. Note that inference is not with respect to 0, but to -0.46 as there is no intercept in the model.
sLDA model with regression coefficients and 95% confidence intervals. Note that inference is not with respect to 0, but to -0.46 as there is no intercept in the model.Abstract
Objective: Text-based responses may provide significant contributions to suicide risk prediction, yet research including text data is limited. This may be due to a lack of exposure and familiarity with statistical analyses for this data structure. Method: The current study provides an overview of data processing and statistical algorithms for text data, guided by an empirical example of 947 online participants who completed both open-ended items and traditional self-report measures. We give an introduction to a number of text-based statistical approaches, including dictionary-based methods, topic modeling, word embeddings, and deep learning. Results: We analyze responses from the open-ended question “How do you feel today?”, detailing characteristics of the responses, as well as predicting past-year suicidal ideation. Conclusions: We see the analysis of text from social media, open-ended questions, and other text sources (i.e., medical records) as an important form of complementary assessment to traditional scales, shedding insight on what we are missing in our current set of questionnaires, which may ultimately serve to improve both our understanding and prediction of suicide.
Kenneth Tyler Wilcox
Statistical Consultant
My research interests include integrative data analysis, meta-analysis, topic modeling, Bayesian statistics, multilevel modeling, statistical programming, and psychology.