Supervised latent Dirichlet allocation with covariates: A Bayesian structural and measurement model of text and covariates
Abstract
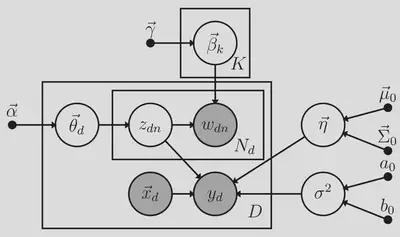
Text is a burgeoning data source for psychological researchers, but little methodological research has focused on adapting popular modeling approaches for text to the context of psychological research. One popular measurement model for text, topic modeling, uses a latent mixture model to represent topics underlying a body of documents. Recently, psychologists have studied relationships between these topics and other psychological measures by using estimates of the topics as regression predictors along with other manifest variables. While similar two-stage approaches involving estimated latent variables are known to yield biased estimates and incorrect standard errors, two-stage topic modeling approaches have received limited statistical study and, as we show, are subject to the same problems. To address these problems, we proposed a novel statistical model — supervised latent Dirichlet allocation with covariates (SLDAX) — that jointly incorporates a latent variable measurement model of text and a structural regression model to allow the latent topics and other manifest variables to serve as predictors of an outcome. Using a simulation study with data characteristics consistent with psychological text data, we found that SLDAX estimates were generally more accurate and more efficient. To illustrate the application of SLDAX and a two-stage approach, we provide an empirical clinical application to compare the application of both the two-stage and SLDAX approaches. Finally, we implemented the SLDAX model in an open-source R package to facilitate its use and further study.
Kenneth Tyler Wilcox
Statistical Consultant
My research interests include integrative data analysis, meta-analysis, topic modeling, Bayesian statistics, multilevel modeling, statistical programming, and psychology.