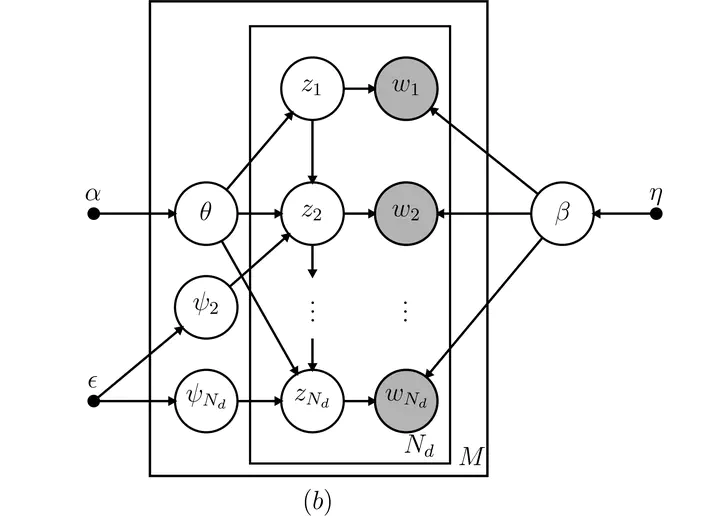
 Directed acyclic graph of the HTMM model.
Directed acyclic graph of the HTMM model.Abstract
Topic models are a state-of-the-art probabilistic approach to extracting structural information about discrete data and have been used with great success for text mining. A recent development in topic modeling, the Hidden Topic Markov Model (HTMM), incorporates hidden Markov models, resulting in contiguous topic assignments and word sense disambiguation. This is a departure from the standard ‘bag-of-words’ assumption of the seminal Latent Dirichlet Allocation (LDA). While LDA can handle word synonymy, it restricts each word to belong to a single topic. HTMM is capable of assigning a given word to multiple topics depending on location within a document. An expectation-maximization (EM) algorithm for inference was proposed by Gruber, Rosen-Zvi, and Weiss (2007) that takes advantage of existing EM techniques for hidden Markov models, but a full derivation was never published. I derive the special state space used by HTMM and approach inference for HTMM in two ways: First, a full derivation of an EM algorithm for frequentist inference and second, a novel Gibbs sampler for Bayesian inference.
Kenneth Tyler Wilcox
Statistical Consultant
My research interests include integrative data analysis, meta-analysis, topic modeling, Bayesian statistics, multilevel modeling, statistical programming, and psychology.