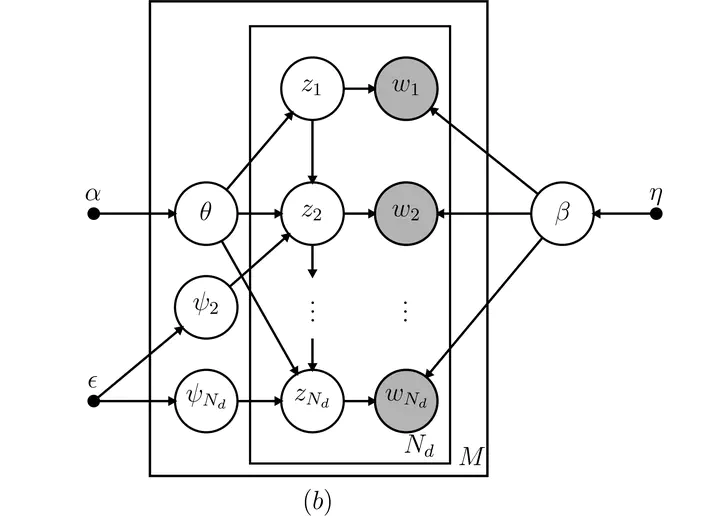
 Directed acyclic graph of the HTMM model.
Directed acyclic graph of the HTMM model.Abstract
Topic models are a probabilistic approach to extracting structural information from discrete data and have been used with great success for text mining. The topic model is a mixture model that represents a collection of words (i.e., a document) as a mixture of topic-specific distributions over the words. A recent development in topic modeling, the Hidden Topic Markov Model (HTMM), incorporates hidden Markov models to model contiguous latent topics and better handle word sense disambiguation. This is a departure from the standard ‘bag-of-words’ assumption of the seminal Latent Dirichlet Allocation (LDA) model and has been shown to have better predictive accuracy for new documents and qualitatively more interpretable topics. We detail the state space model used by the HTMM and propose a Gibbs sampling algorithm for Bayesian inference. The performance of the Gibbs sampler and an EM algorithm are compared in a simulation study. The HTMM is demonstrated on an empirical data set and compared to LDA. Unlike LDA, the HTMM is capable of modeling dependency among the latent topics in a corpus of documents. The topic distributions can be used for a variety of goals including identification of similar documents, network analysis, and identification of key topics in a corpus. The HTMM and related topic models offer a fully probabilistic statistical framework for modeling textual data that often results from open-ended questionnaires, diaries, interviews, and other information-rich sources of data that cannot be easily analyzed with traditional statistical methods.
Kenneth Tyler Wilcox
Statistical Consultant
My research interests include integrative data analysis, meta-analysis, topic modeling, Bayesian statistics, multilevel modeling, statistical programming, and psychology.