Bayesian supervised topic modeling with covariates
The temporal and financial resources needed to qualitatively analyze textual data can be prohibitive. However, a growing collection of quantitative modeling approaches for text offer potential alternatives. One latent variable approach, topic modeling, assumes that text can be summarized as a mixture of latent categories (i.e., topics; Blei, Ng, & Jordan, 2003). By representing patterns of word co-occurrences as topics, major themes and features of the text can be extracted and studied on their own or used as variables in subsequent analyses. Applications of topic modeling in psychological research include prediction of students’ test scores (Kim, Kwak, & Cohen, 2017; Kim, Kwak, Cardozo-Gaibisso, Buxton, & Cohen, 2017), understanding open-ended survey questions regarding sources of anxiety (Rohrer, Brümmer, Schmukle, Goebel, & Wagner, 2017), and, in conjunction with item-response theory models, prediction of clinical diagnoses (He, 2013).
Many applications estimate topics and then use them as predictors in later regression models. However, this two-stage procedure ignores variability in the latent topic estimates which can produce biased estimates and incorrect Type I error rates for the regression coefficients. Blei and McAuliffe (2010) proposed a one-stage model, supervised topic modeling (SLDA), wherein the latent topics predict an observed outcome and showed that it can outperform two-stage approaches. However, SLDA does not allow for the inclusion of additional predictors of the outcome which limits its utility for psychological research. Therefore, we extended SLDA to jointly estimate a latent variable model of the text and a regression model to predict an outcome using both the latent topics and additional predictors. The SLDAX model consists of two primary components: (1) a topic model for the text and (2) a regression model predicting the outcome using the topics and additional predictors. See Figure 1 for a graphical representation of the model and Figure 2 for the model as a generative process.
To estimate the SLDAX model, we analytically derived a Gibbs sampling algorithm. We further implemented the model in an R package to help researchers adopt the model. To evaluate the model and the Gibbs estimation method, we conducted a simulation study based on an SLDAX model with a continuous predictor ($x_1$), a dichotomous predictor ($x_2$), and $K$ topics giving the following regression model for individual $d$’s outcome $y_d$,
$$y_d \sim Normal \left( \eta_{x_1} x_{1d} + \eta_{x_2} x_{2d} + \sum_{k=1}^{K} \eta_{\bar{z}_k} \bar{z}_{kd}, \sigma^2 \right),$$
where $x_{1d}$ and $x_{2d}$ are observed scores on predictor $x_1$ and $x_2$, respectively, and we denote regression coefficients by $\eta_j$. We generated latent empirical topic probabilities $\bar{z}_{1d}, \ldots, \bar{z}_{Kd}$ from the process in Figure 1 with $\alpha$ and $\gamma$ set to vectors of ones. We generated independent predictors $x_{1d} \sim \text{Normal}(0, 1)$ and $x_{2d} \sim \text{Bernoulli}(0.5)$ such that $x_1$ and $x_2$ were independent of the topics. We manipulated the number of topics (2 or 5), number of documents (50 and 150), vocabulary size (500 and 1,000), average document length (75 and 250 words), effect size for $\eta_{\bar{z}_1}$ (multiple partial correlation of 0% and 13.04% (“medium” effect; Cohen, 1988)), and $\Sigma_0$ ($I$ and $1,000 I$ where $I$ is an identity matrix). We fixed $\eta_{x_1}$ and $\eta_{x_2}$ to “medium” effects, $\eta_{\bar{z}_k}$ to 0 for $k > 1$, and the total variance of $y$ to 1. Through the simulation, we found that the regression coefficient estimates were unbiased in all conditions except for estimates of $\eta_{\bar{z}_1}$, which were negatively biased toward zero when modeling shorter documents with a five-topic model. Type I error rates for $\eta_{\bar{z}_1}, \ldots, \eta_{\bar{z}_K}$ were close to the nominal rate of 5% except when modeling shorter documents with a five-topic model, for which Type I error rates were conservative (< 2%). Power for $\eta_{x_1}$ and $\eta_{x_2}$ always exceeded 80%. Power for $\eta_{\bar{z}_1}$ exceeded 80% for a two-topic model in all conditions and for a five-topic model with larger sample sizes. This study is the first to propose a joint model of textual data and prediction of an outcome using both observed predictors and latent topics to represent textual data. Our model allows for one-stage estimation of the latent variable model for the text and a regression model linking the latent variables and other predictors to an outcome. Our simulation results suggest that the proposed Gibbs sampler for SLDAX yields accurate estimates of the regression coefficients, well-controlled Type I error rates, and desirable power even with small sample sizes and short documents while protecting against over-fitting. These results provide useful sample size and document length guidelines for researchers considering incorporating textual data into their studies while the R package facilitates the use of the SLDAX model.
Figure 1. Directed acyclic graphical representation of the SLDAX model
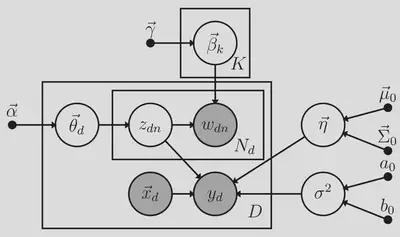
Figure 2. Generative process for the SLDAX model.
We assume a vocabulary of V unique words and let $\bar{z}_{kd} = N_d^{-1} \sum_n I(z_{dn} = k)$ be the empirical topic proportions where $I()$ is an indicator function equal to 1 if its predicate is true and 0 otherwise.
Draw $(p + K)$ regression coefficients $\eta \sim \text{Normal} \left(\mu_0, \Sigma_0 \right)$,
Draw residual variance $\sigma^2 \sim \text{Inverse-Gamma}(a_0, b_0)$,
For topic $k = 1, \ldots, K$:
- 3.1) Draw $V$ word probabilities $\beta_k \sim \text{Dirichlet} (\gamma)$,
- For document/individual $d = 1, \ldots, D$:
4.1) Draw $K$ topic proportions $\theta_d \sim \text{Dirichlet}(\alpha)$,
4.2) For word $n = 1, \ldots, N_d$:
4.2.1) Draw topic indicator $z_{dn} \sim \text{Categorical} (\theta_d)$,
4.2.2) Draw word $w_{dn} | z_{dn} = k \sim \text{Categorical}(\beta_k)$,
4.3) Draw outcome $y_d \sim \text{Normal} \left(\sum_{j=1}^p \eta_j x_{jd} + \sum_{k=1}^K \eta_{p+k} \bar{z}_{kd}, \sigma^2 \right)$.
References
Blei, D. M., & McAuliffe, J. D. (2010). Supervised topic models. ArXiv:1003.0783 [Stat]. Retrieved from https://arxiv.org/abs/1003.0783
Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent Dirichlet Allocation. Journal of Machine Learning Research, 3, 993–1022. https://doi.org/10.1162/jmlr.2003.3.4-5.993
Cohen, J. (1988). Multiple regression and correlation analysis. In Statistical power analysis for the behavioral sciences (2nd ed., pp. 407–467). Hillsdale, NJ: Lawrence Erlbaum Associates.
He, Q. (2013). Text mining and IRT for psychiatric and psychological assessment (Dissertation). University of Twente. https://doi.org/10.3990/1.9789036500562
Kim, S., Kwak, M., Cardozo-Gaibisso, L., Buxton, C., & Cohen, A. S. (2017). Statistical and qualitative analyses of students’ answers to a constructed response test of science inquiry knowledge. Journal of Writing Analytics, 1(1), 82–102. Retrieved from https://journals.colostate.edu/index.php/analytics/article/view/120/87
Kim, S., Kwak, M., & Cohen, A. S. (2017). A mixture partial credit model analysis using language-based covariates. In L. A. van der Ark, M. Wiberg, S. A. Culpepper, J. A. Douglas, & W. C. Wang (Eds.), Quantitative Psychology (pp. 321–333). https://doi.org/10.1007/978-3-319-56294-0_28
Rohrer, J. M., Brümmer, M., Schmukle, S. C., Goebel, J., & Wagner, G. G. (2017). “What else are you worried about?” – Integrating textual responses into quantitative social science research. PLoS ONE, 12(7), e0182156. https://doi.org/10.1371/journal.pone.0182156
Kenneth Tyler Wilcox
Statistical Consultant
My research interests include integrative data analysis, meta-analysis, topic modeling, Bayesian statistics, multilevel modeling, statistical programming, and psychology.